— почти никому неизвестные;
— разработанные одним человеком;
— заброшенные.
«EventQL is a distributed, column-oriented database built for large-scale event collection and analytics. It runs super-fast SQL and JavaScript queries».
Open-source с 26 июля 2016
https://github.com/eventql/eventql (963 звезды)
Написана на C++11
Для координации используется ZooKeeper
Кроме ZooKeeper нет зависимостей
MPP, Distributed, Column-Oriented...
Scales to petabytes. Fast range scans...
Almost complete SQL 2009 support.
Real-time Inserts & Updates.
Automatic distributed partitioning.
ChartSQL.
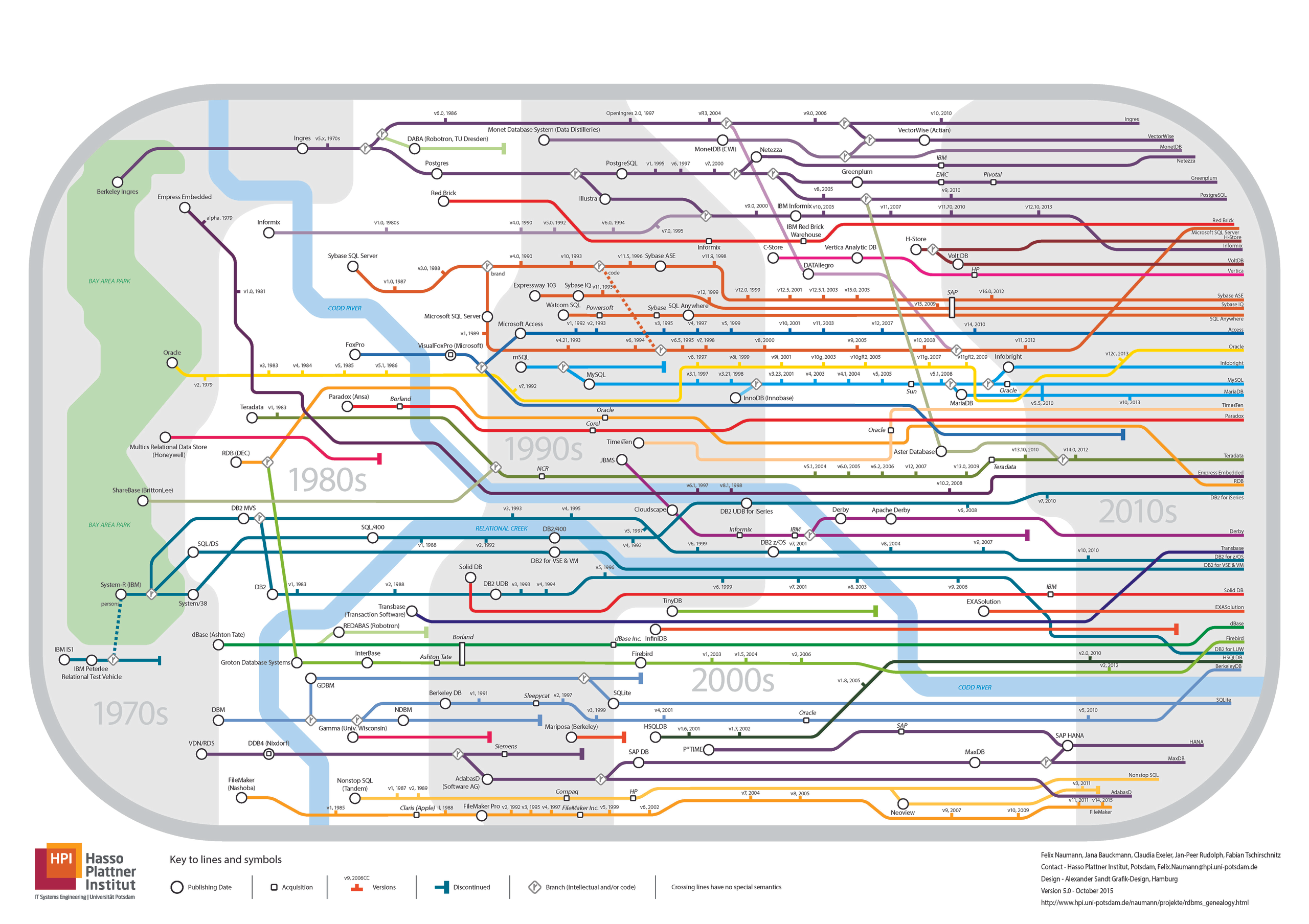
Последний коммит 4 мая 2017.
Сайт http://eventql.io/ не загружается.
Последняя issue на GitHub с вопросом о развитии — без ответа.
Принадлежит компании DeepCortex, Берлин.
Один C++ разработчик, один фронтенд разработчик.
Активная разработка с 2014 года.
Лицензия AGPL.
Меньше года в open-source, продукт заброшен.
— разработчик перешёл в другую компанию?
— у компании поменялись приоритеты?
— изменились жизненные обстоятельства?
— причиной open-source является
отсутствие развития внутри компании?
— просто надоело?
ChartSQL вдохновил реализацию работы с графиками в интерфейсе Tabix для ClickHouse.
Интересные статьи про архитектуру системы в блоге
(читать можно через web.archive.org или в дереве исходников).
Грамотная организация кода — есть чему поучиться.
Изначально — ålenkå.
GPU database engine
https://github.com/antonmks/Alenka (1103 звезды)
Написана на CUDA, C++
Один разработчик — Антон Старобинский (antonmks), Минск
Лицензия Apache 2.0
Есть JDBC драйвер от Technica Corporation
Open-source, с 26 января 2012
Последний коммит — ноябрь 2016
Личный проект
Система является исследовательским прототипом
Слабо расширяемая кодовая база
Тесты Mark Litwintschik:
http://tech.marksblogg.com/alenka-open-source-gpu-database.html
Почему заброшена?
— разработчик перешёл в компанию nVidia.
Повышение интереса к технологиям GPU баз данных
Возможность использования для исследований
Смотрите также:
MapD (сейчас назвается OmniSci):
https://github.com/mapd/ (Apache 2.0)
Open-source с 8 мая 2017
https://www.mapd.com
PGStorm: https://github.com/heterodb/pg-strom (GPLv2)
BrytlytDB: https://www.brytlyt.com/ (closed source)
Kinetica DB:
https://www.kinetica.com/ (closed source)
Полиматика BI:
https://www.polymatica.ru/ (closed source)
FPGA. Пример: Kickfire (компания закрылась)
Набор инструкций DAX (SQL in Silicon) в процессорах SPARC
(разжатие + фильтрация)
Offload фильтрации на уровень SSD:
https://www.vldb.org/pvldb/vol9/p924-jo.pdf
«Аналитическая база данных для несортированных данных»
https://github.com/viyadb/viyadb (Apache 2.0)
Написана на C++17
Open-source с 28 февраля 2018
Один разработчик — Michael Spector
Хорошая подготовка запуска:
https://habrahabr.ru/post/350154/
Medium, LinkedIn, Hacker News...
Последний коммит — 26 апреля 2018
Данные целиком в RAM
Работа над агрегированными данными
Слабая поддержка SQL (изначально — запросы в JSON)
Для обработки запросов динамически генерируется код на C++
Есть кластер, для координации используется Consul
Существует проприетарная система с очень похожим названием:
SAS Viya
Мне не удалось разобраться, является ли это совпадением или нет.
Исходит из противоречивых предпосылок:
«Only in-memory database can handle random writes accompanied with analytical queries, which require full table scans».
— https://medium.com/viyadb/analyzing-mobile-users-activity-with-viyadb-c88a02104269
Только в in-memory БД возможно постоянное добавление событий, поступающих неупорядоченным по времени потоком и одновременная обработка аналитических запросов.
???
Система достойна изучения?
 Пример: кодогенерация на C++
Пример: кодогенерация на C++
... но, см. также:
DBToaster:
https://dbtoaster.github.io/ (Apache 2.0)
исследовательская разработка EPFL (Швейцария)
Кодогенерация C++ vs. LLVM
Пример: MemSQL поменяли механизм с C++ на LLVM
в версии 5 (30 марта 2016)
http://blog.memsql.com/memsql-5-ships/
Пример: Cloudera Impala изначально использует LLVM для кодогенерации
Пример: ClickHouse использует зачаточный механизм кодогенерации на C++, но в основном полагается на векторную обработку запросов.

«LucidDB is the first and only open-source RDBMS purpose-built entirely for data warehousing and business intelligence».
https://github.com/LucidDB (Apache 2.0, ранее GPLv2)
Компания: The Eigenbase Project (США), некоммерческая организация
+ компания LucidEra (поставщик BI)
Java, немного C++
Последний коммит 6 лет назад
Что было 6 лет назад?
Хорошо расширяемая кодовая база
Более одного разработчика
Хорошая документация (http://www.eigenbase.org/ не загружается, часть доступна на web.archive.org)
Богатая функциональность, хорошая поддержка SQL
Почему умерло?
— отсутствие финансирования;
— нет энтузиастов;
— компания LucidEra закрылась;

Apache Calcite — «фронтенд» для SQL СУБД
(парсинг, анализ запросов, оптимизация,
query plan, JDBC)
Используется в Hive, Drill, Kylin, Samza, Storm, MapD...


Изначально closed-source
Разработка компании Calpont
Октябрь 2013 — релиз в open-source, GPL 2.0
Октябрь 2014 — банкротство Calpont
https://github.com/infinidb/infinidb
Последний коммит — сентябрь 2014
MariaDB ColumnStore
https://github.com/mariadb-corporation/mariadb-columnstore-server


«Extreme Scale Transaction Processing»
http://www.infinisql.org/ (сайт доступен)
https://github.com/infinisql/infinisql (GPL 3.0, было AGPL)
Написана на C++
Два разработчика
Open-source — 25 ноября 2013
Последний коммит — 12 января 2014
OLTP, in-memory
Есть кластер. Нет отказоустойчивости.
Базовая поддержка SQL
Личный проект.
Недоделана, заброшена.
Почему заброшена?
— выпуск в open-source был мотивирован надеждой привлечь энтузиастов к проекту, что обречено на провал;
— разработка СУБД — это сложно, долго и дорого.

«The open-source database for the realtime web»
Document-oriented (JSON)
Правильно реализована репликация (RAFT) и шардирование
Поддержка подписки на realtime обновления
Удобный язык запросов ReQL и клиентские библиотеки
Написана на C++
Классный сайт: https://rethinkdb.com/
https://github.com/rethinkdb/rethinkdb/
Разрабатывается с 2009 года
Приличное количество разработчиков
Отличная документация
Активное сообщество
20 938 звёзд на GitHub!
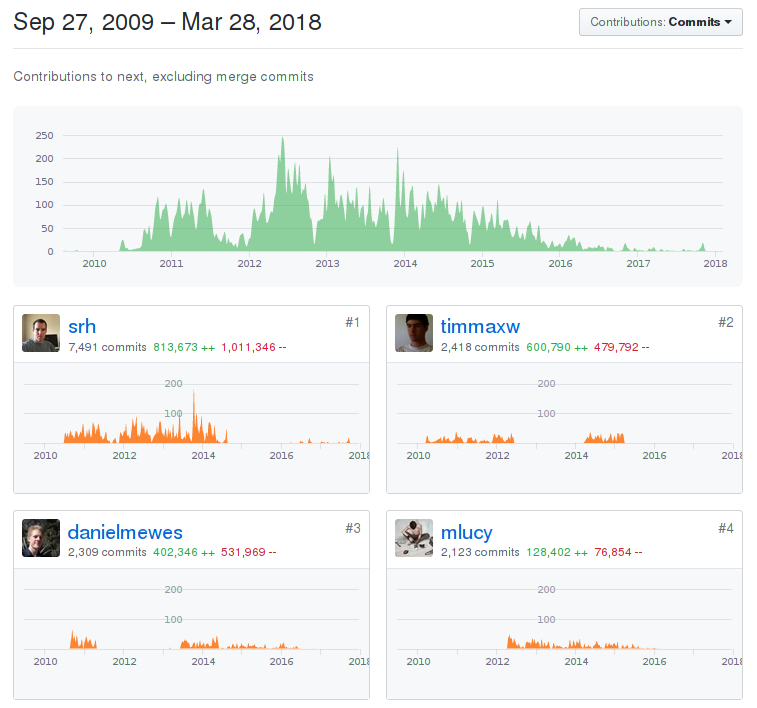
2009 — основание компании, инвестиции
Трудности с позиционированием,
отсутствие коммерческой успешности.
Октябрь 2016 — закрытие компании,
команда разработки переходит в Stripe
Февраль 2017 — благодаря пожертвованиям, удалось выкупить права на RethinkDB и передать их в The Linux Foundation.
Лицензия изменена с AGPL на Apache 2.
2017-2018 — разработка продолжается, но гораздо более вяло.
Рассказ об ошибках от основателя компании:
http://www.defmacro.org/2017/01/18/why-rethinkdb-failed.html

«Native XML Database System»
Разработка ИСП РАН
https://github.com/sedna/sedna (Apache 2.0)
Последний коммит — 2013

GOODS, POST++, ShMem, FastDB, GigaBASE, MiniDB, PERST, DyBASE...
IMCS (In-Memory Columnar Store)
https://github.com/knizhnik/imcs
Расширение для PostgreSQL для хранения
и обработки временных рядов
Use-case — биржевые данные.
Слабая интеграция с SQL (по сути, свой язык внутри Postgres).
Личный проект: изменение обстоятельств, потеря интереса, недооценка трудозатрат.
Стартап: отсутствие ниши, сложность позиционирования на рынке, потеря финансирования.
Сторонний продукт компании:
— уход ключевых разработчиков;
— прекращение поддержки разработки open-source;
— выкладка в open-source в связи с банкротством;
— выкладка в open-source по недоразумению.
Институт: исследовательский проект, исследование завершено.
1. Масштабирование разработки.
2. Понятное позиционирование.
3. Фокусировка на конкретной нише.
4. Надёжная поддержка родительской компании.
5. Неограничительная лицензия.
6. Преимущества должны исходить из фундаментальных причин.
7. Поддержка развития сообщества.
