arrayJaccardIndex

:) SELECT arrayJaccardIndex(
tokens('ClickHouse is a database'),
tokens('ClickHouse is a good database'))
0.8
Developer: FFFFFFFHHHHHHH.
1. (55 min) What's new in ClickHouse 23.7.
+ guest talks!
2. (5 min) Q&A.
ClickHouse Summer Release.
— 31 new features 🌞
— 16 performance optimizations 🕶️
— 47 bug fixes ⛱️
:) SELECT initCap('what is this?');
What Is This?
:) SELECT initcapUTF8('унылая хрень');
Унылая Хрень
:) SELECT initcapUTF8('好的数据库');
好的数据库
* Not safe for Turkish.
Developer: Dmitry Kardymon.
:) SELECT hasSubsequence('ReplicatedMergeTree', 'RepMT');
1
:) SELECT hasSubsequenceCaseInsensitive(
'Clickstream Data Warehouse', 'ClickHouse');
1
:) SELECT hasSubsequenceCaseInsensitiveUTF8(
'не прислоняться', 'не слонЯ');
1
Developer: Dmitry Kardymon.
SELECT extract(text, '^[^\n]+') FROM articles;
SELECT substring(text, 1, position('\n' IN text) - 1) FROM articles;
SELECT firstLine(text) FROM articles;
Developer: Dmitry Kardymon.
:) SELECT arrayJaccardIndex(
tokens('ClickHouse is a database'),
tokens('ClickHouse is a good database'))
0.8
Developer: FFFFFFFHHHHHHH.
SYSTEM STOP LISTEN QUERIES HTTPS
— TCP, TCP WITH PROXY, TCP SECURE,
HTTP, HTTPS, MYSQL, GRPC,
POSTGRESQL, PROMETHEUS, CUSTOM,
INTERSERVER HTTP, INTERSERVER HTTPS,
QUERIES ALL, QUERIES DEFAULT, QUERIES CUSTOM;
SYSTEM START LISTEN QUERIES ALL ON CLUSTER default
Developer: Nikolai Degterinskiy.
keeper_server:
log_storage_disk: log_s3_plain
latest_log_storage_disk: log_local
snapshot_storage_disk: snapshot_s3_plain
latest_snapshot_storage_disk: snapshot_local
Only the latest log requires local storage.
Previous logs and all snapshots can use S3 (with the s3_plain disk type).
— to keep the local storage space small and bounded (~100 MB);
— supports migration between disks;
Developer: Antonio Andelic.
keeper_server:
enable_reconfiguration: 1
Allows to choose between reconfiguration by editing the configuration file
and by sending the reconfig command.
It is compatible with the ZooKeeper protocol.
All clients supporting ZooKeeper's reconfig will work with Keeper.
Developer: Michael Kot.
A normal CSV:
"Name","Is It Good","Stars","LOC","Contributors"
ClickHouse,Yes,29990,800000,1300
MongoDB,No,,,
A weird CSV:
"Name","Is It Good","Stars","LOC","Contributors"
ClickHouse,Yes,29990,800000,1300
MongoDB,No
To parse a weird CSV,
SET input_format_csv_allow_variable_number_of_columns = 1.
Developer: Dmitry Kardymon.
Similar to RowBinary, but allows encoding the absense of values.
0x00 encoded_value
^ when the value is present
0x01
^ when the value is absent
Allows to calculate table's DEFAULT expressions on per-record basis.
Note: you can also utilize the input_format_null_as_default setting.
But NULL and the absense of a value are different.
Developer: Pavel Kruglov.
:) SELECT * FROM hits INTO OUTFILE 'hits.parquet'
23.6: 325.50 thousand rows/s., 270.16 MB/s.
23.7: 1.57 million rows/s., 1.30 GB/s.
6 times faster!
Developer: Michael Kolupaev.
chdb: Auxten & Lorenzo Mangani;
BigHouse: Dan Goodman;
If you want to demonstrate your project on the ClickHouse Webinar,
write to [email protected] or connect with us on https://clickhouse.com/slack
Automatically attached in clickhouse-local.
$ clickhouse-local
# ClickHouse 1.1 (2017)
:) SELECT * FROM file('test.csv', CSVWithNames, 'a String, b String')
# ClickHouse 22.1 (2022)
:) SELECT * FROM file('test.csv', CSVWithNames)
# ClickHouse 23.1 (2023)
:) SELECT * FROM file('test.csv')
# ClickHouse 23.7 (2023)
:) SELECT * FROM `test.csv`
Developer: Aleksey Golub.
Can be created on the server,
using the files in the user_files directory:
CREATE DATABASE files ENGINE = Filesystem;
CREATE DATABASE files ENGINE = Filesystem('subdir/');
SELECT * FROM files.`path/to/file.avro.zst`;
And there are S3 and HDFS database engines 😍
CREATE DATABASE s3 ENGINE = S3;
CREATE DATABASE bucket ENGINE = S3('https://clickhouse-public-datasets.s3.amazonaws.com/');
SELECT * FROM
s3.`https://clickhouse-public-datasets.s3.amazonaws.com/hits_compatible/hits.csv.gz`;
SELECT * FROM bucket.`hits_compatible/hits.csv.gz`;

Experimental support in ClickHouse.
:) SET dialect = 'prql';
:) from tracks
select [album_id, name, unit_price] | sort [-unit_price, name]
group album_id (aggregate [track_count = count, album_price = sum unit_price])
join albums (==album_id)
group artist_id (
aggregate [track_count = sum track_count, artist_price = sum album_price])
join artists (==artist_id)
select [artists.name, artist_price, track_count] | sort [-artist_price]
derive avg_track_price = artist_price / track_count | take 10;
Try it... and maybe, it will work.
Developer: János Benjamin Antal.
Now available for browsers and CloudFlare workers!
Btw, you can use ClickHouse without any drivers,
using just fetch or even XMLHttpRequest.
But with ClickHouse.js, you get:
— streaming;
— types for TypeScript (e.g., typed settings)
— ready-to-use examples.

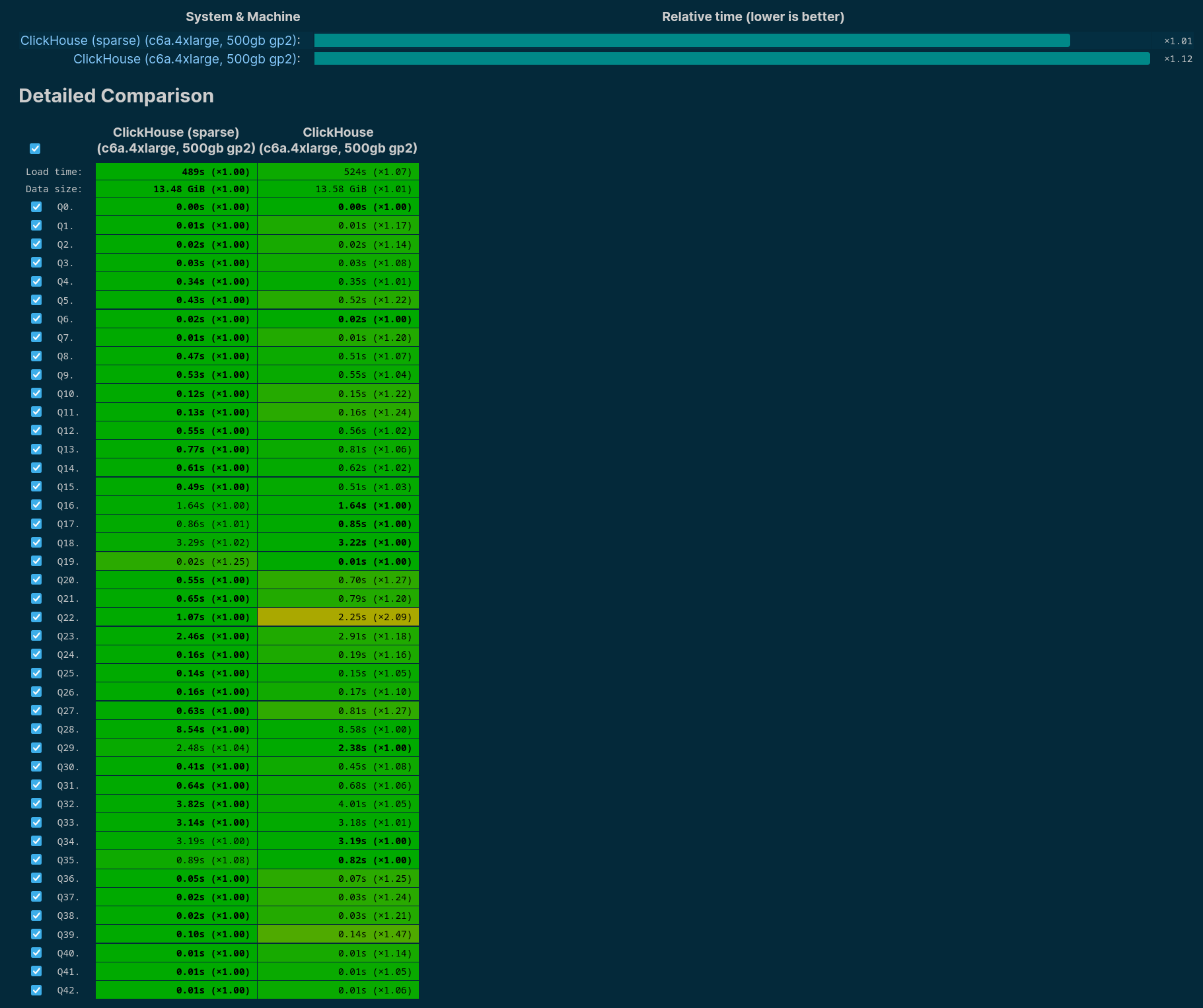
— Vantage's Journey from Redshift and Postgres
to ClickHouse
— How we built the Internal Data Warehouse
at ClickHouse
— Real-time event streaming with ClickHouse,
Confluent Cloud and ClickPipes
Video Recordings: https://www.youtube.com/c/ClickHouseDB