# This is a text format:
$ clickhouse-client -q "SELECT * FROM table FORMAT JSON"
# This is a binary format, and we are writing into a file:
$ clickhouse-client -q "SELECT * FROM table FORMAT Parquet" > file.parquet
# This is a binary format, and we are writing to the terminal:
$ clickhouse-client -q "SELECT * FROM table FORMAT Parquet"
The requested output format `Parquet` is binary and could produce side-effects when output directly into the terminal.
If you want to output it into a file, use the "INTO OUTFILE" modifier in the query or redirect the output of the shell command.
Do you want to output it anyway? [y/N]
Developer: Alexey Milovidov.
Highlighting Trailing Spaces
:) SELECT 'Hello, ' AS a, 'World\n ' AS b;
How will this look like in the CLI?
Demo
Controlled by the output_format_pretty_highlight_trailing_spaces setting.
Developer: Alexey Milovidov.
Rendering Multi-Line Values
:) SELECT 'Hello' AS a, 'Beautiful\nWorld' AS b
UNION ALL SELECT 'World', 'Goodbye' FORMAT Pretty;
How will this look like in the CLI?
Demo
Controlled by the output_format_pretty_multiline_fields setting.
Developer: Alexey Milovidov.
Shortening Column Names
In Pretty formats:
:) SELECT time::Date,
uniq(data.headers.`cf-connecting-ip`),
uniq(data.url)
FROM website_traffic
WHERE time >= yesterday() GROUP BY 1 ORDER BY 1
┌─CAST(time, 'Date')─┬─uniq(data.he⋯necting-ip)─┬─uniq(data.url)─┐
1. │ 2025-01-27 │ 897995 │ 65974 │
2. │ 2025-01-28 │ 246953 │ 21596 │
└────────────────────┴──────────────────────────┴────────────────┘
Developer: Alexey Milovidov.
Enhanced Compression Autodetection
# The easiest way to convert data between formats.# The compression is automatically detected from file names:
$ ch --copy < data.csv.gz > data.jsonl.zst
# Process the data and convert it on the fly:
$ ch --query "
SELECT * FROM table WHERE upyachka != 'fail'
" < data.avro.gz > result.parquet
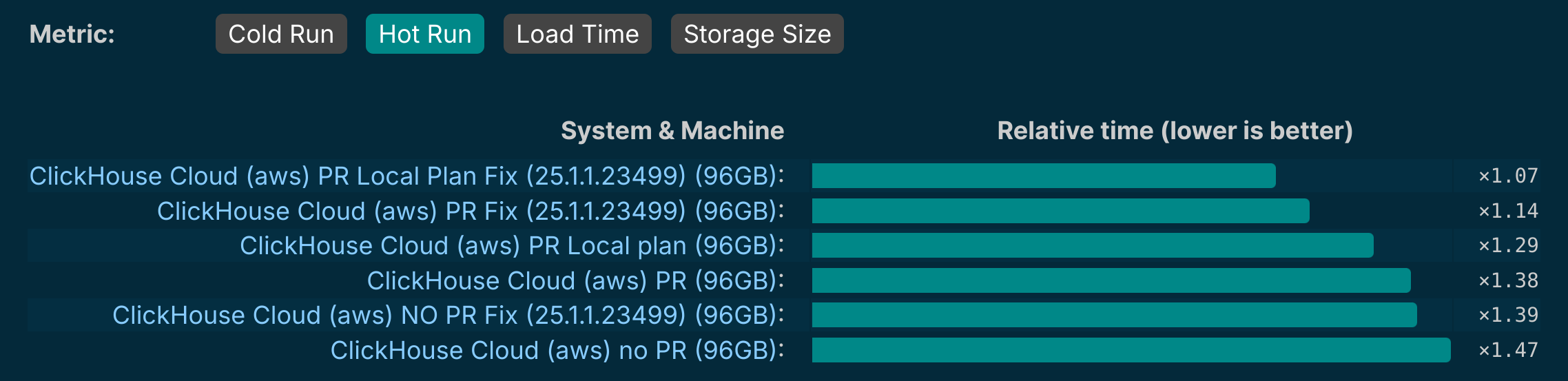
Parallel Hash Join is the default algorithm since 24.12.
Now it is faster. Demo.
Developer: Nikita Taranov.
Faster Vector Indices
Using the new, secondary index cache, Controlled by server settings,
skipping_index_cache_size and skipping_index_cache_max_entries.
Example: a table with 33,114,778 embeddings of 768 dimensions:
Full scan: 216 sec.
Indexed search (without the cache): 33 sec.
Indexed search (with the cache): 0.064 sec 🚀
Developers: Robert Schulze, Michael Kolupaev.
Faster Parallel Replicas
ClickHouse 25.1 — 40% improvement on ClickBench!
Parallel Replicas (enabled with the enable_parallel_replicas setting) allow to use the resources of all replicas for a single query, to speed up heavy queries, especially in the case of operating on a shared storage.
Developers: Igor Nikonov, Nikita Taranov.
trace_log Is Symbolized
system.trace_log table contains traces from the Sampling Profiler, embedded in ClickHouse.
The Sampling Profiler collects information about where the query is spending time, as well as where did it allocate memory,
and allows collecting flame graphs down to the level of individual queries, or up to aggregations over time across the cluster.
In ClickHouse 24.12, it contains addresses in the machine code, that could be transformed to code locations on the fly using the addressToLine and addressToSymbol functions. This information is invalidated on every release.
In ClickHouse 25.1, there are persisted symbols and lines columns, so the analysis can be done across different builds.
Developer: Alexey Milovidov.
Something Interesting
Lightweight Updates
Aka "on the fly mutations".
SET apply_mutations_on_fly = 1;
Now all ALTER UPDATE/DELETE will be applied on the fly on SELECT queries, even before the corresponding operations have been fully materialized.
Developer: Anton Popov.
This feature has been already enabled for the customers of ClickHouse Cloud for more than a year. Now it is implemented for the regular MergeTree and ReplicatedMergeTree engines.
Auto Increment
CREATE TABLE test
(
id UInt64 DEFAULT generateSerialID('test'),
data String
)
ORDER BY id;
INSERT INTO test (data) VALUES VALUES ('Hello'), ('World');
The new, generateSerialID function implements named distributed counters
(stored in Keeper), which can be used for auto-increments in tables.
It is fast (thanks to batching) and safe for parallel and distributed operation.
Developer: Alexey Milovidov.
Better Merge Tables
The Merge table engine allows to unify multiple tables as one.
Also available as a merge table function.
CREATE TABLE t1 (a UInt8, b String) ENGINE = Memory;
CREATE TABLE t2 (a Int32, c Array(String)) ENGINE = Memory;
CREATE TABLE merge_table ENGINE = Merge(currentDatabase(), '^t(1|2)$');
SELECT * FROM merge_table;
SELECT * FROM merge('^t(1|2)$');
In version 24.12, Merge tables took the structure of the first table (unless the structure was explicitly specified).
In version 25.1, Merge tables make a union of columns of all tables.
It even unifies data types to a common type or a Variant data type.
Developer: Alexey Milovidov.
Streaming Events Over HTTP
$ curl http://localhost:8123/ -d "SELECT number % 3 AS k, count()
FROM numbers(1e9) GROUP BY k WITH TOTALS FORMAT JSONEachRowWithProgress"
{"progress":{"read_rows":"74631669","read_bytes":"597053352","total_rows_to_read":"1000000000","elapsed_ns":"100040117"}}
{"progress":{"read_rows":"151160199","read_bytes":"1209281592","total_rows_to_read":"1000000000","elapsed_ns":"200065327"}}
{"progress":{"read_rows":"227754138","read_bytes":"1822033104","total_rows_to_read":"1000000000","elapsed_ns":"300115954"}}
{"progress":{"read_rows":"304348077","read_bytes":"2434784616","total_rows_to_read":"1000000000","elapsed_ns":"400193152"}}
{"progress":{"read_rows":"380680380","read_bytes":"3045443040","total_rows_to_read":"1000000000","elapsed_ns":"500227569"}}
...
{"progress":{"read_rows":"762472713","read_bytes":"6099781704","total_rows_to_read":"1000000000","elapsed_ns":"1000340080"}}
{"progress":{"read_rows":"838870425","read_bytes":"6710963400","total_rows_to_read":"1000000000","elapsed_ns":"1100394164"}}
{"progress":{"read_rows":"914548638","read_bytes":"7316389104","total_rows_to_read":"1000000000","elapsed_ns":"1200466502"}}
{"progress":{"read_rows":"990880941","read_bytes":"7927047528","total_rows_to_read":"1000000000","elapsed_ns":"1300489758"}}
{"progress":{"read_rows":"1000000000","read_bytes":"8000000000","total_rows_to_read":"1000000000","elapsed_ns":"1312531422"}}
{"meta":[{"name":"k","type":"UInt8"},{"name":"count()","type":"UInt64"}]}
{"row":{"k":0,"count()":"333333334"}}
{"row":{"k":1,"count()":"333333333"}}
{"row":{"k":2,"count()":"333333333"}}
{"totals":{"k":0,"count()":"1000000000"}}
Developer: Alexey Milovidov.
Streaming Events Over HTTP
The formats JSONEachRowWithProgress, JSONStringsEachRowWithProgress stream newline-delimited JSON events, where each event is one of: progress, meta, row, totals, extremes, exception, as soon as they appear.
Works properly with Transfer-Encoding: chunked, even with HTTP compression (Content-Encoding: gzip/deflate/brotli/zstd).
Demo.
Developer: Alexey Milovidov.
Note: these formats already existed, but the implementation didn't work as I wanted.
Bonus
chDB 3.0
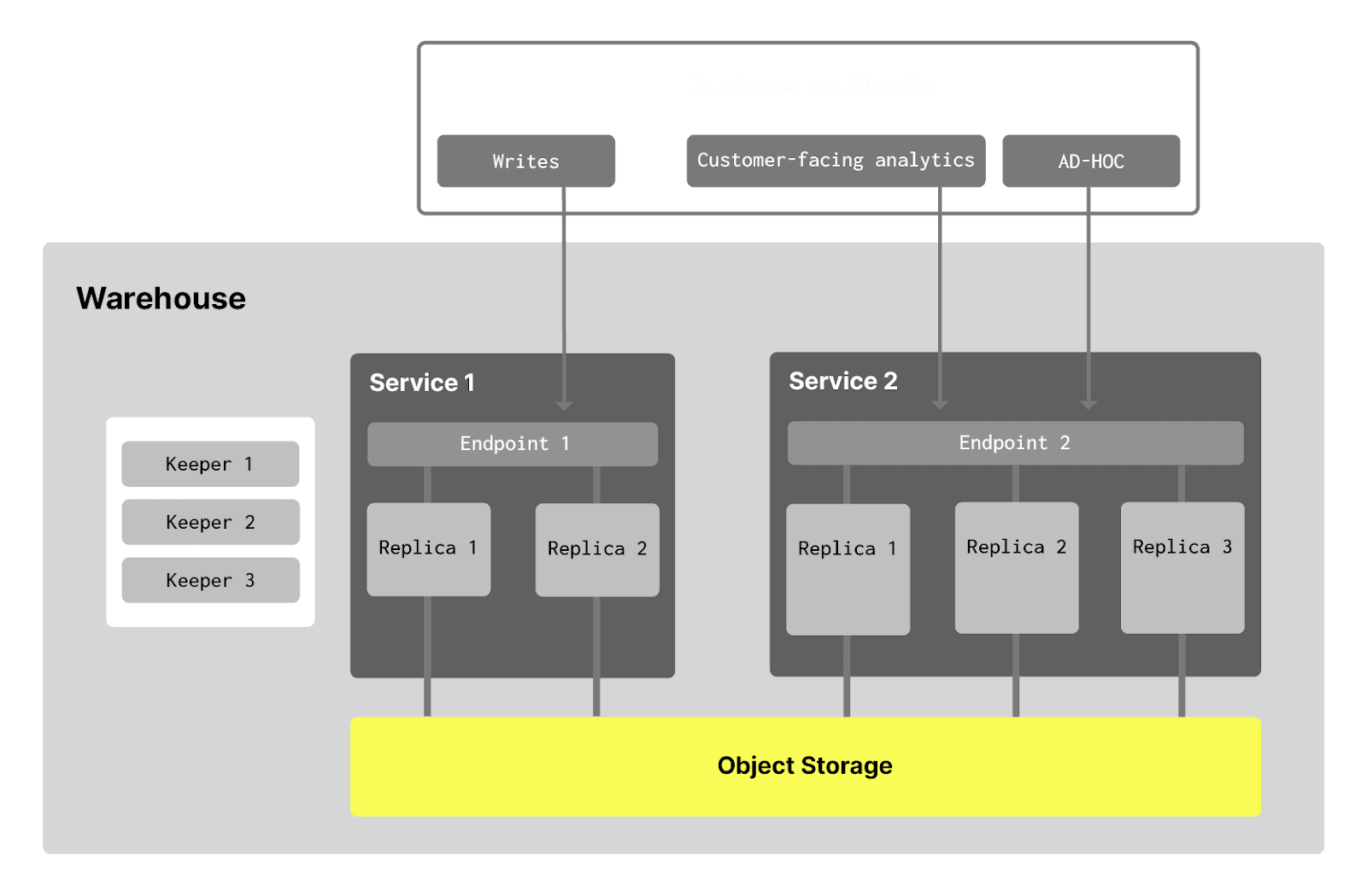
Compute-Compute Separation
What Else?
We sped up reading from Iceberg!
No comments. Install 25.1 and try it by yourself.
Developer: Dan Ivanik.
Integrations
ClickPipes supports column renaming.
JDBC driver improves standard compliance and reliability.
dbt now supports Refreshable Materialized Views.
Grafana has initial support for Variant, Dynamic, and JSON data types.
Go client fully supports Variant, Dynamic, and JSON data types.
A template for Dataflow for transferring from BigQuery to ClickHouse.
Meetups
— 🇭🇷 Zagreb, Jan 30th — 🇧🇪 FOSDEM, Brussels, Feb 1, 2 — 🇮🇳 Mumbai, Feb 1st — 🇬🇧 London, Feb 5th — 🇮🇳 Bangalore, Feb 8th — 🇦🇪 Dubai, Feb 10th
— Evolution of the Cloud
— Compute-compute separation
— The journey for ARM support
— BuzzHouse — Fuzzing ClickHouse
— Medalion architecture for BlueSky
— Evidence.dev with ClickHouse
— Solving problems with monitoring dashboards
— IBM, M3ter, AMP, Increff...